Most of the cost in a modern broadcast plant is not the cameras or the playout. It is the chain in between: the routers, frame syncs, format converters, and dedicated encoders that move uncompressed video from point A to point B without dropping a frame. SMPTE-2110 was supposed to make that chain cheaper by replacing SDI with IP. In practice, the gear that speaks 2110 fluently still looks a lot like the gear that spoke SDI: appliance-shaped, vendor-locked, and priced accordingly.
That is what made the NVIDIA DGX Spark interesting to us. It ships as an entry-level AI development platform, but what sits inside the chassis is a pair of 200G ConnectX-7 NICs and a Blackwell GPU. Those are exactly the two parts you need to build a SMPTE-2110 node.
This post is about why the hardware works, what we ran into, and what it means for anyone trying to operate a modern 2110 plant without a six-figure equipment budget per node.
A quick refresher on SMPTE-2110#
SMPTE 2110 is the standard for carrying live, professional media over IP. It is what replaced SDI inside modern broadcast facilities. Instead of one cable per signal, the plant runs commodity Ethernet and routes individual essence streams as separate IP flows.
The relevant pieces for an ingest node are:
- ST 2110-20 carries uncompressed video, typically as 10-bit YUV422 over RTP. A single 1080p59.94 stream is about 2.5 Gbps. A single UHD stream is roughly 12 Gbps. Multicast is the norm.
- ST 2110-30 carries uncompressed PCM audio, again over RTP, in independently routable flows.
- ST 2110-10 defines the timing model. Every device on the plant locks to a shared PTP grandmaster (IEEE 1588) so frames and samples line up across the network.
The implication for hardware: a 2110 node needs serious NIC bandwidth, a way to receive RTP without dropping packets, hardware-assisted PTP, and a path from the NIC to the processor that does not melt the CPU. That is a tall order for general-purpose servers. It is why the established 2110 ecosystem leans on FPGA-backed appliances and proprietary SDKs.
What the DGX Spark actually has inside it#

The Spark (NVIDIA’s GB10) ships with the kind of specs that broadcast engineers usually pay an order of magnitude more to assemble:
- Dual ConnectX-7 200GbE NICs. Hardware timestamping, kernel-bypass capable, RDMA-ready. 400 Gbps of aggregate bandwidth is enough headroom for many uncompressed UHD streams in parallel.
- Blackwell GPU. Native YUV422 processing on the GPU itself, plus hardware NVENC for the encode ladder. The same silicon that AI workloads use for tensor math is happy to do real-time video.
- Compact form factor. Small enough to live in an OB van, a venue rack, or a half-shelf at the edge of a broadcast plant.
- Low power draw. Practical for venues and trucks where power and cooling are constrained.
What NVIDIA built for AI developers turns out to be broadcast-grade network capacity and a real-time YUV processing engine in the same chassis. The hardware was already there. We just had to convince it to think it was a 2110 endpoint.
From a 2110 endpoint to a full air chain#
A 2110 ingest node on its own is a building block. Operators do not deploy building blocks; they deploy air chains. Getting from one to the other takes two more pieces, both of which jeket ships as first-class parts of the platform.
Built-in NMOS registry. NMOS is how operators discover, route, and control 2110 flows on a plant. Jeket runs the registry itself, and every device on the network registers with it: our own DGX Spark ingest nodes, plus third-party encoders, cameras, switchers, and gateways from any vendor. The registry exposes every sender and receiver (AMWA IS-04), and operators issue connection management commands (IS-05) through jeket to wire flows together across the entire plant. We are not just a 2110 endpoint. We are the control plane the rest of the plant binds to.
MXL data plane. Above 2110, essence movement on a jeket air chain runs through MXL, our software-defined media exchange. MXL is what carries video and audio between nodes, applies processing, and feeds the encoder. It is the layer that makes the air chain composable rather than wired.
Three pieces make up what we mean by an end-to-end air chain: SMPTE-2110 endpoints, NMOS for control, and MXL for the data plane. Operators design and run them as a single graph in the air chain editor:
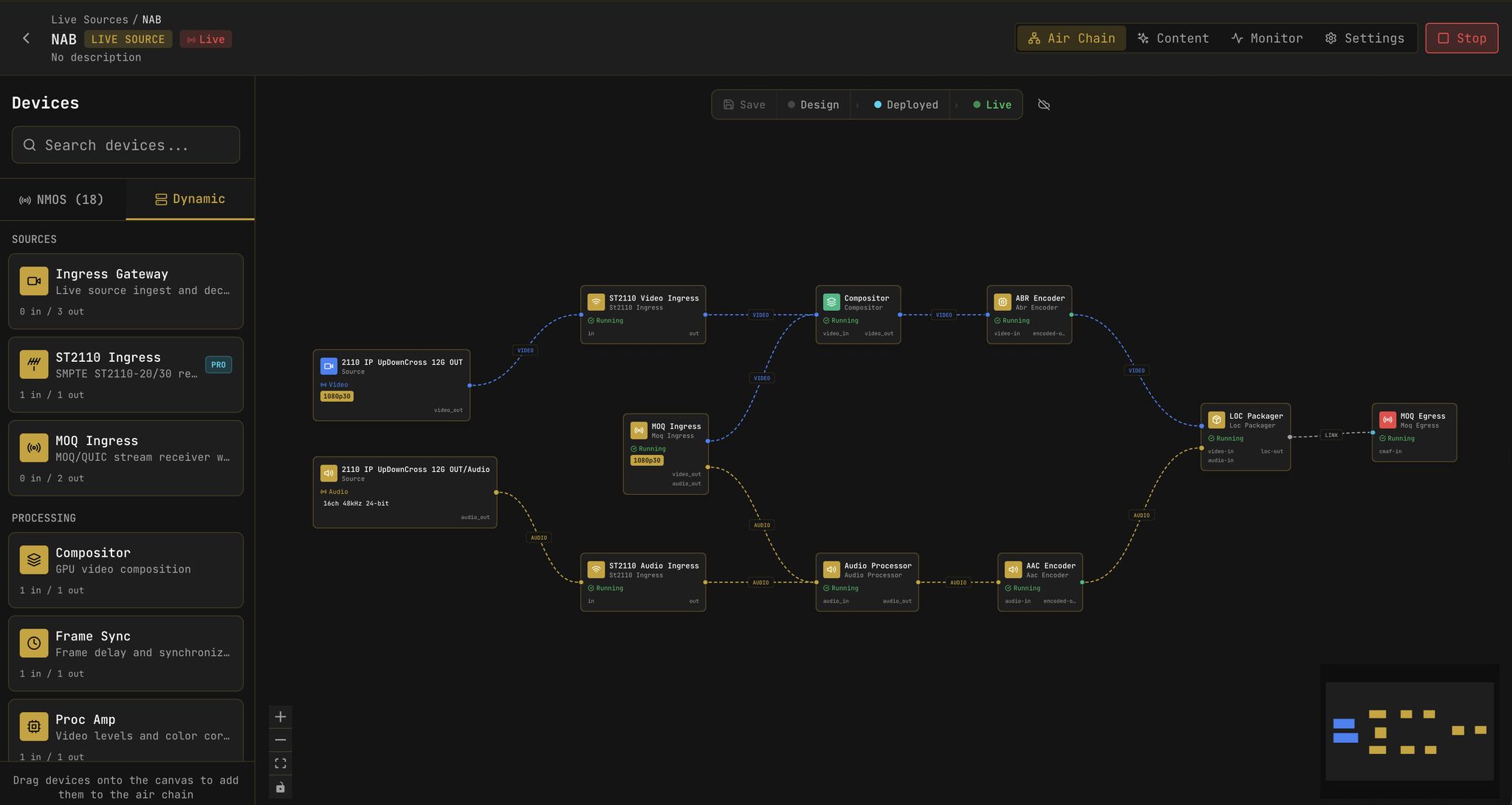
Kubernetes underneath, failover by default#
Every component in a jeket air chain runs as a pod on Kubernetes. The DGX Spark is a node in the cluster. The 2110 ingress containers, compositors, frame syncs, encoders, and packagers in the editor sidebar are dynamic pods that the scheduler can place on any node with the right hardware. Operators wire an air chain in the editor; jeket compiles it into pod specifications; the cluster reconciles to the desired state. Need more capacity? Add a node. Need to swap an encoder version? Roll the deployment.
Media failover is a first principle, not an add-on. A real broadcast chain cannot drop a frame because a pod restarted. Jeket’s data plane carries redundant flows where it matters: ingress paths can pull from primary and backup 2110 senders simultaneously, compositors can hot-swap upstream sources, and the encoder ladder continues to publish during pod migration. When something does fail, the failover happens in the data plane, not by waiting for Kubernetes to schedule a new pod and replay the stream from scratch.
The result for an operator: the operational model of modern software (declarative, observable, one revision away from rollback) with the failover behavior of broadcast hardware.
What this means for broadcast economics#
A traditional 2110-capable ingest and encode chain stitches together NIC cards with FPGA offload, dedicated frame synchronizers, standalone encoding appliances, and the SDKs that tie them together. Every box is a vendor relationship, a software contract, an RMA process, and a point of failure. The chain is also where engineering time goes to die: most of the work is coordinating between systems that were never designed to talk to each other.
Collapsing that chain onto a single GPU box does three things:
- Capex drops. A reference node is in the low five figures, not low six.
- Failure modes shrink. One operating system, one observability surface, one update cadence.
- The edge gets viable. Sports venues, concert halls, corporate campuses, and houses of worship can run a real 2110 ingest node on-site, without backhauling raw video to a central facility.
One node is interesting. Three becomes a powerhouse. A 3+ node DGX Spark cluster delivers real redundancy through Kubernetes HA, media failover handled in the data plane, parallel GPU capacity for compositing and ABR encoding, and headroom for the AI workloads that NVIDIA designed the hardware around in the first place. That is a complete broadcast cluster in a half-rack, for what a single specialized appliance used to cost.
Book a 30-min Demo